AWS Glue Explained for Beginners
AWS Glue: The Way I Finally Understood It
When I started learning AWS Glue, I kept seeing new terms like:
Glue Context
DynamicFrame
Data Catalog
Crawler
Job
Notebook
And honestly, it felt overwhelming 😵💫.
I already knew pandas and a bit of PySpark, so my biggest confusion was:
“Why is Glue adding new things? Isn’t Spark already enough?”
This blog is my attempt to explain AWS Glue the way I finally understood it, in a simple and practical way.
🔹 First: What Problem Does AWS Glue Solve?
We all know:
pandas → great for small data
Spark / PySpark → used when data is too big to fit in memory
Spark works by:
Splitting data
Processing it across multiple worker nodes
Coordinated by a driver (master)
But managing Spark clusters yourself is:
Hard
Expensive
Operationally painful
👉 AWS Glue solves this by giving us Spark as a managed, serverless service.
You focus on ETL logic, AWS handles infrastructure.
🔹 AWS Glue Is Basically “Managed Spark”
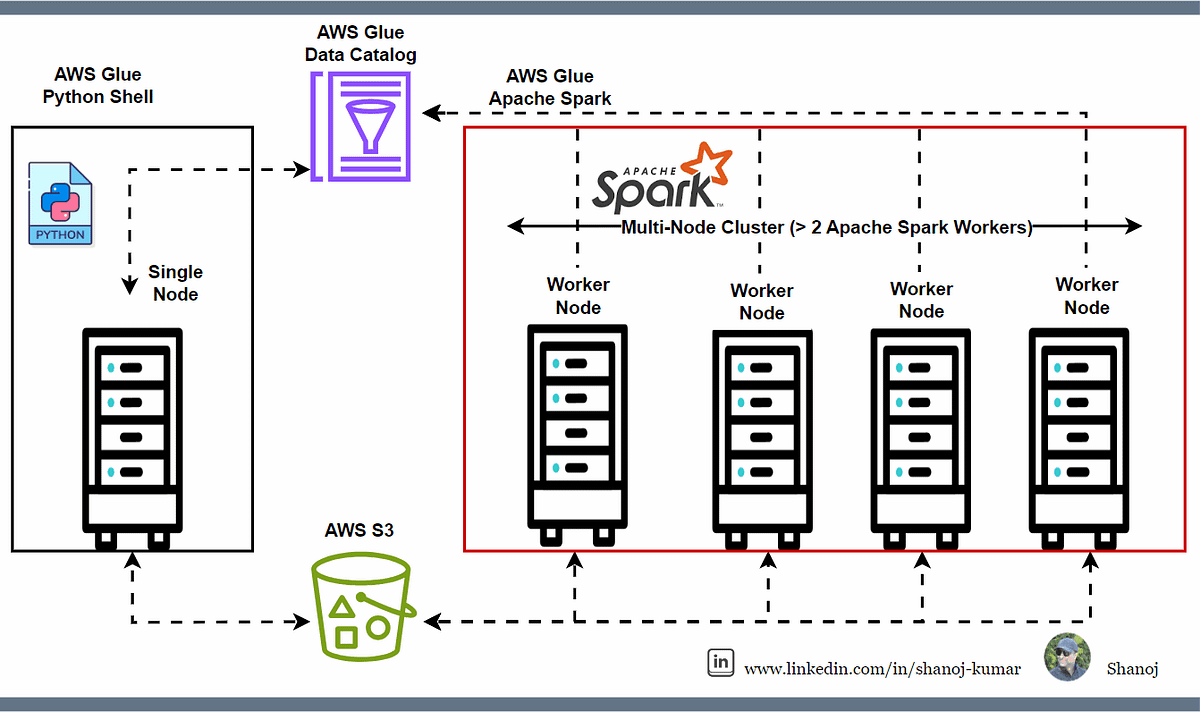
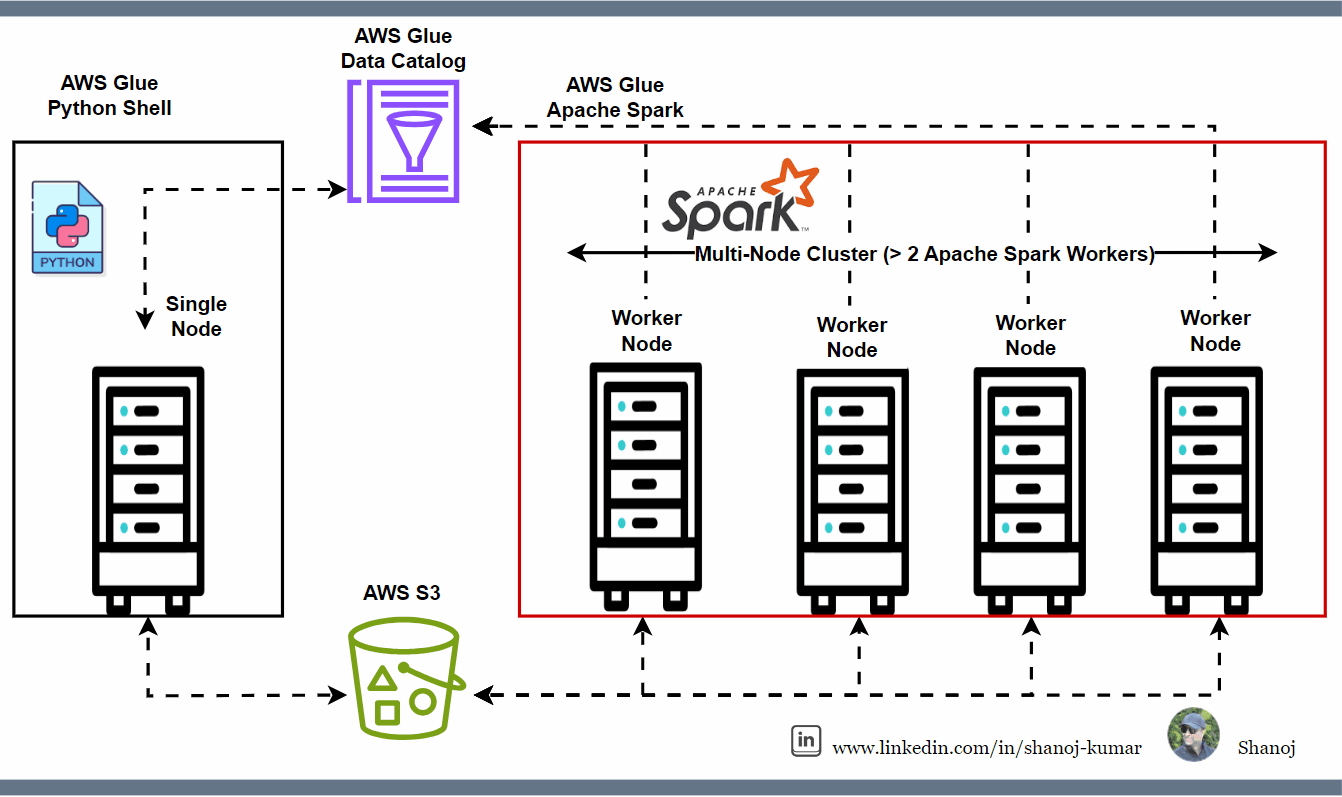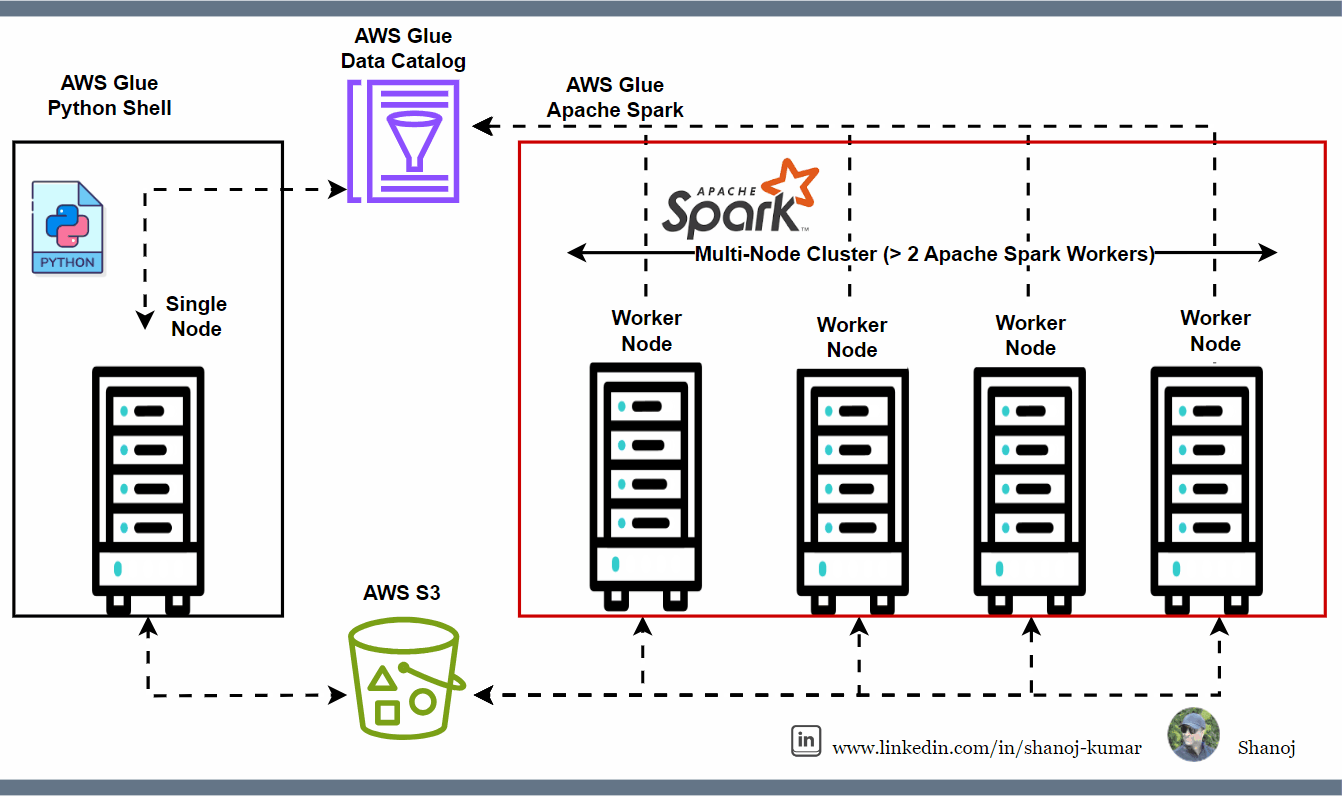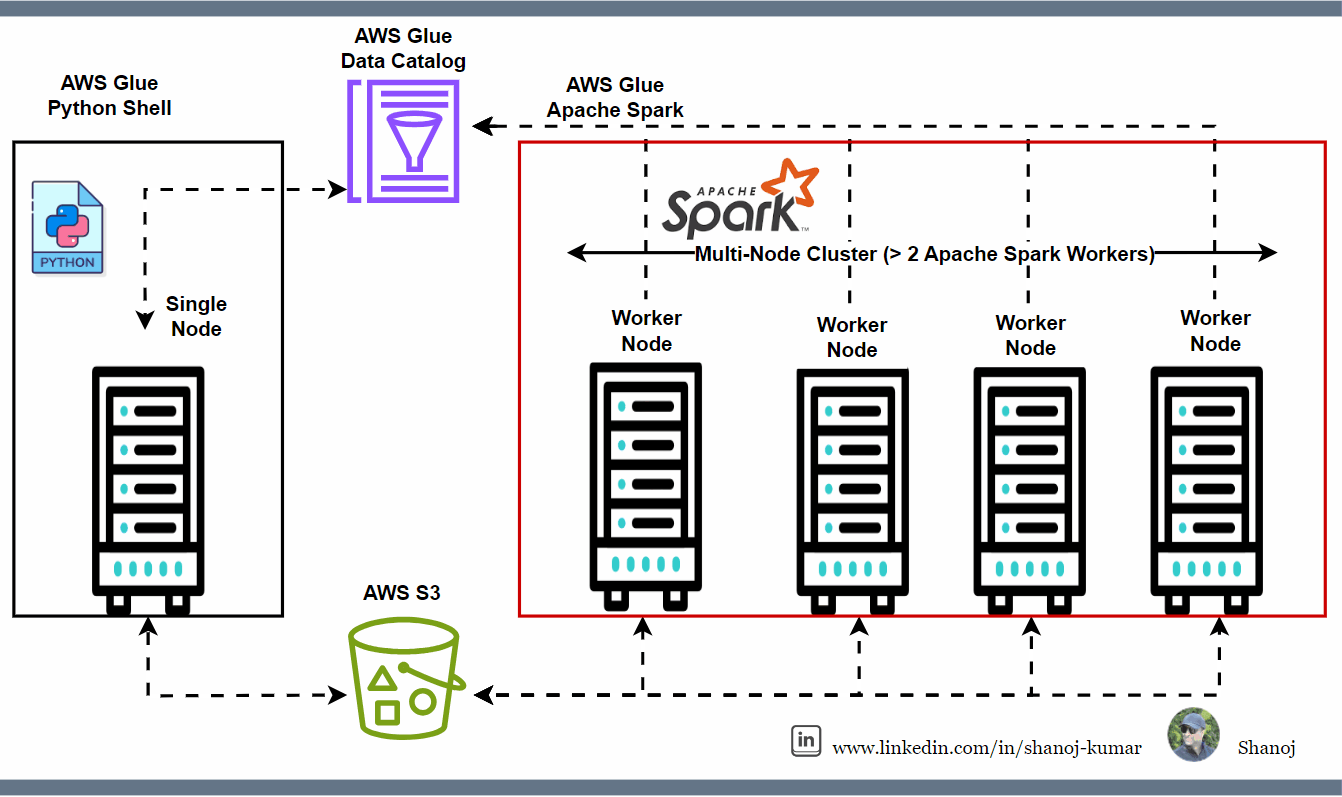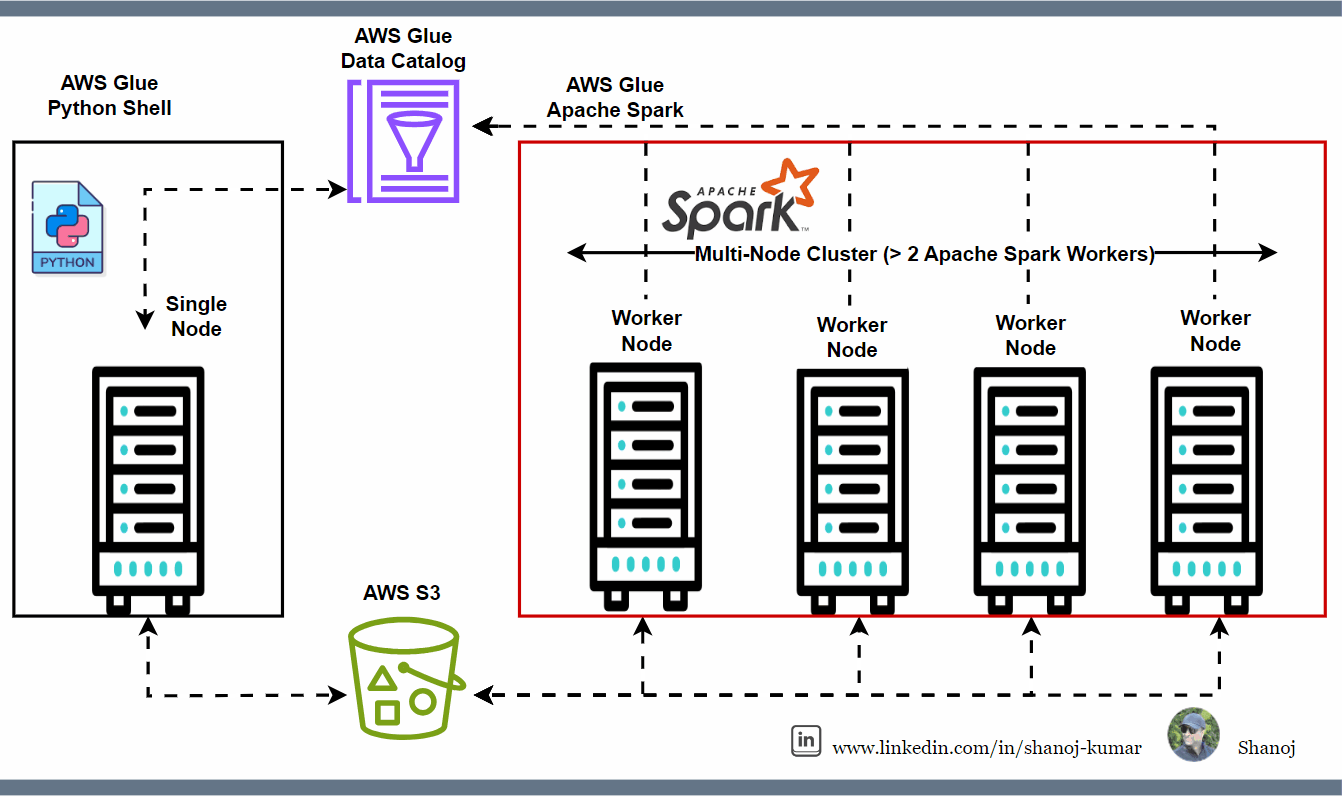
Important clarification:
Serverless does NOT mean small data
It means you don’t manage servers
AWS Glue:
Uses Apache Spark internally
Runs on multiple nodes
Can process GBs to TBs of data
AWS creates and destroys the cluster automatically
🔹 Main Components of AWS Glue
Let’s break Glue into simple building blocks.
1️⃣ Glue Crawler – The Scanner


A Crawler:
Scans data in S3 / RDS / Redshift
Figures out:
Schema (columns & types)
File format
Partition structure
Stores this info in Glue Data Catalog
❗Crawler does NOT process data
It only understands data.
👉 Think of it as:
“Scan first, process later”
2️⃣ Glue Data Catalog – The Brain
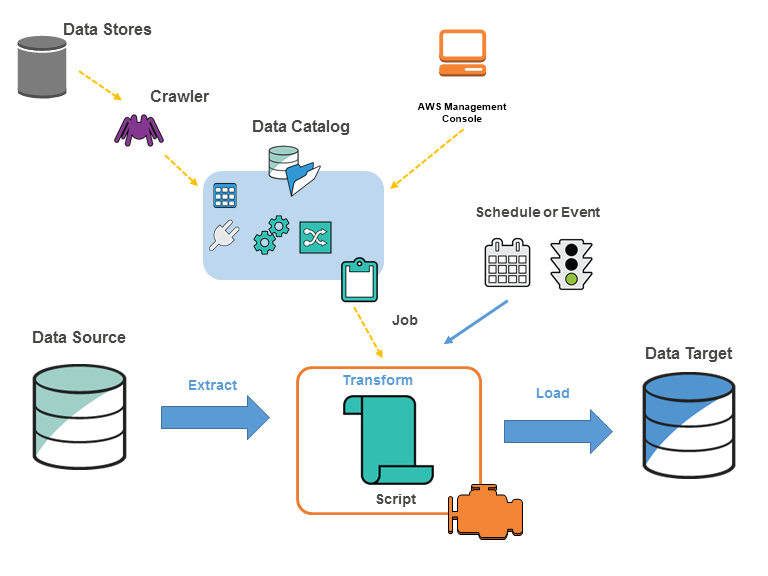
The Glue Data Catalog is a metadata store.
It does NOT store data.
It stores information ABOUT data:
S3 location
Schema
Partitions
File format
Mental model 🧠
If your data is a book 📘
Glue Catalog is the table of contents
🔹 Why Glue Data Catalog Is So Important
Because multiple services depend on it:
AWS Glue Jobs
Glue Notebooks
Amazon Athena
Redshift Spectrum
EMR (via Hive metastore)
👉 It’s the single source of truth for your data lake
3️⃣ Athena + Glue Catalog (Behind the Scenes)
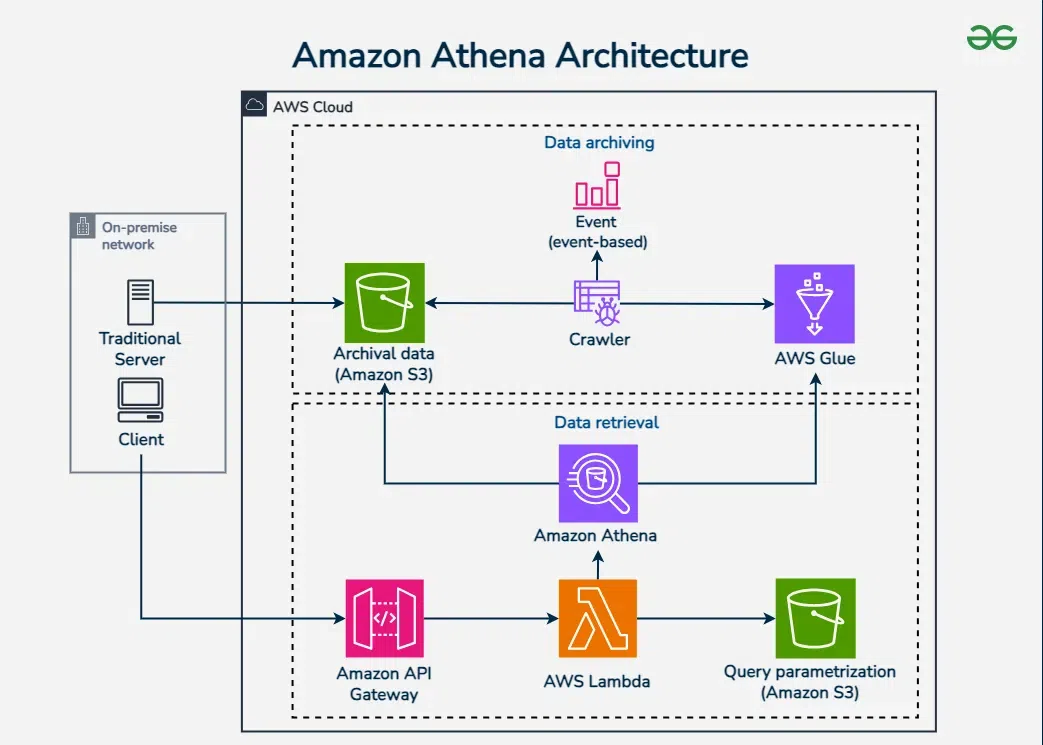

When you run a query in Athena:
SELECT * FROM sales WHERE year = 2025;
Athena:
Reads schema & location from Glue Catalog
Finds only matching partitions
Reads data directly from S3
Returns results
❗Athena never stores data
❗Athena cannot work without metadata
👉 Glue Catalog makes Athena plug-and-play
4️⃣ Glue Notebook – The Practice Lab
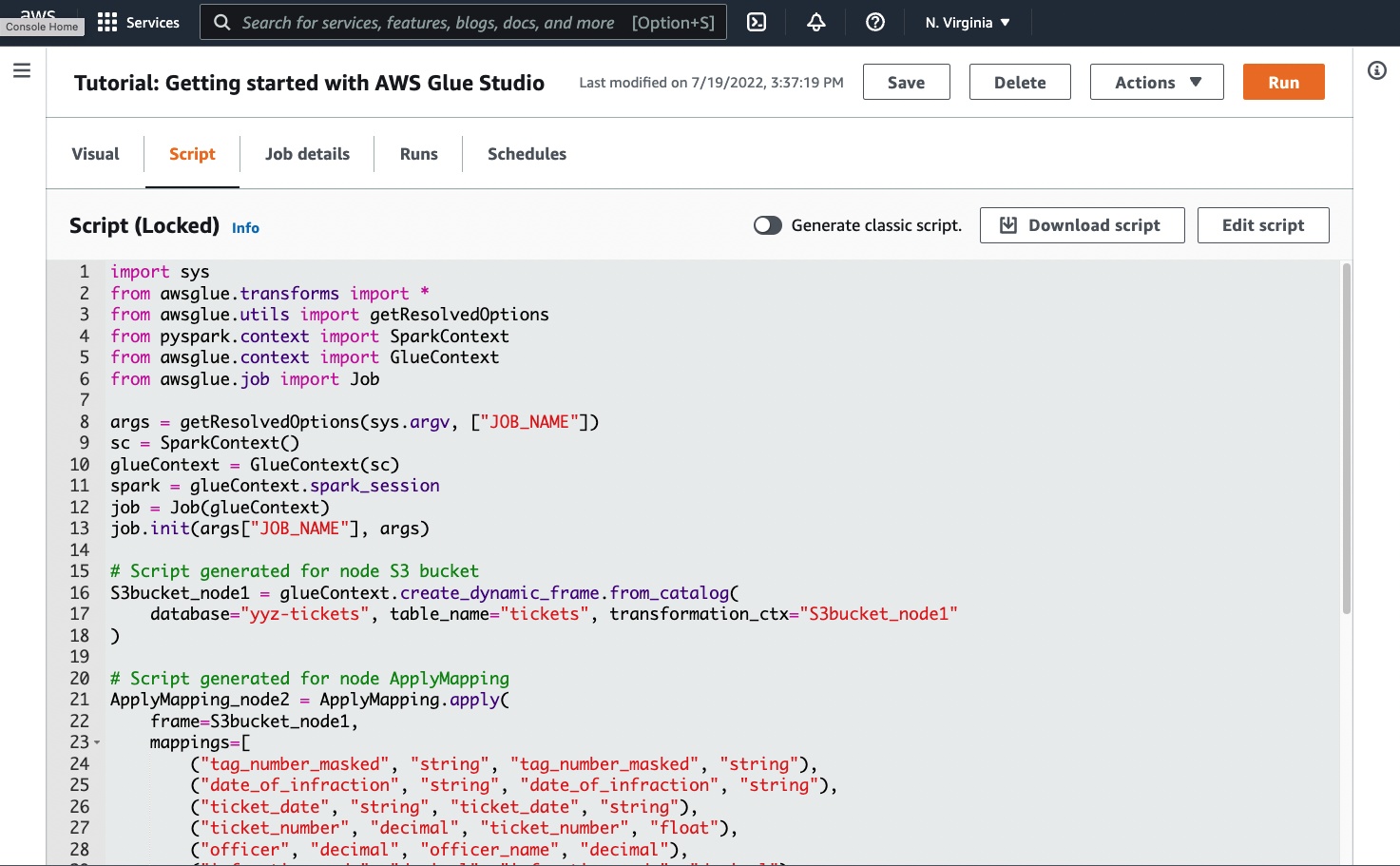
Glue Notebook is:
Like Jupyter Notebook
But runs Spark on AWS Glue
Used for:
Learning
Experimenting
Debugging ETL logic
⚠️ Important:
Notebook runs an interactive Spark cluster
You MUST stop the session after use (to avoid cost)
5️⃣ Glue Job – The Real ETL Machine

A Glue Job is where real ETL happens.
It follows this pipeline:
Extract → Transform → Load (Write)
Examples:
Read raw data from S3
Clean / filter / aggregate
Write processed data back to S3 or Redshift
Glue Jobs:
Are automated
Can be scheduled
Auto-terminate after completion
Safer than notebooks for production
🔹 GlueContext – The Most Confusing (But Important) Part
What is GlueContext?
GlueContext is a Glue-specific wrapper over SparkContext
It helps Spark:
Talk to AWS services
Use Glue Data Catalog
Read/write data easily
Handle schema evolution
📌 GlueContext exists only inside AWS Glue
You will NOT find it in:
Local PySpark
EMR
Databricks
Mental model 🧠
Spark = Engine
GlueContext = AWS Translator
DynamicFrame = Safe container
🔹 DynamicFrame vs Spark DataFrame


| Feature | Spark DataFrame | DynamicFrame |
| Schema | Strict | Flexible |
| Bad records | Fails | Tolerates |
| AWS integration | Manual | Native |
Best Practice ✅
Use Spark DataFrame for transformations
Convert to DynamicFrame for writing
🔹 How Glue Handles Big Data (Workers & Nodes)
Glue uses DPUs (Data Processing Units).
1 DPU ≈
4 vCPU
16 GB RAM
Glue internally creates:
1 driver
Multiple worker nodes
You don’t see them, but they exist.
🔹 Does Glue Automatically Decide Workers?
❌ No — not fully.
You choose:
Worker type
Number of workers
(Optional) auto-scaling limits
Glue will:
Create a Spark cluster using your settings
Run the job
Destroy the cluster
👉 You control cost & scale
🔹 Glue Is Big Data + Serverless (Important)
Glue CAN process TBs of data
It uses distributed Spark
Serverless means:
No cluster setup
No node management
Pay for usage
🔹 Final Mental Model (This Made Everything Click)
S3 → Data
Crawler → Schema
Catalog → Metadata brain
Notebook → Practice
Job → Production ETL
Spark → Processing engine
Glue → Managed Spark
🎯 Final Thoughts
If you:
Know pandas
Understand basic Spark
Learn GlueContext + Catalog
👉 You can write real-world ETL pipelines.
AWS Glue is not magic.
It’s Spark with AWS batteries included 🔋.



